Web Scraper API
Fetch real-time data from 100+ websites,No development or maintenance required.
SCRAPING SOLUTIONS
Get accurate and in real-time results sourced from Google, Bing, and more.
With 120+ prebuilt and custom scrapers ready for any use case.
No blocks, no CAPTCHAs—unlock websites seamlessly at scale.
Execute scripts in stealth browsers with full rendering and automation
PROXY INFRASTRUCTURE
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
SCRAPING SOLUTIONS
PROXY INFRASTRUCTURE
DATA FEEDS
Full details on all features, parameters, and integrations, with code samples in every major language.
LEARNING HUB
ALL LOCATIONS Proxy Locations
TOOLS
RESELLER
Get up to 50%
Contact sales:partner@thordata.com
Products $/GB
Fetch real-time data from 100+ websites,No development or maintenance required.
Get real-time results from search engines. Only pay for successful responses.
Execute scripts in stealth browsers with full rendering and automation.
Bid farewell to CAPTCHAs and anti-scraping, scrape public sites effortlessly.
Dataset Marketplace Pre-collected data from 100+ domains.
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
Data for AI $/GB
Pricing $0/GB
Docs $/GB
Full details on all features, parameters, and integrations, with code samples in every major language.
Resource $/GB
EN $/GB
产品 $/GB
AI数据 $/GB
定价 $0/GB
产品文档 $/GB
资源 $/GB
简体中文 $/GB


In today’s digital world, data is a powerful tool. It drives decisions, informs strategies, and helps businesses grow. Facebook, with its billions of active users, is a goldmine of valuable information that companies can tap into. Whether you’re tracking consumer behavior, analyzing trends, or researching competitors, a Facebook data scraper is an essential tool that can help you extract this information efficiently.
But what exactly is a Facebook data scraper? How can it help you improve your business strategies? And what should you look for when choosing the right tool? In this guide, we’ll explore everything you need to know about Facebook data scraping, its benefits, and how to leverage this tool to gain insights for your business. Let’s dive in!
A Facebook data scraper is a tool or software that allows you to extract data from Facebook. This can include public information from posts, comments, likes, shares, and even profile details. By using a scraper, businesses can collect massive amounts of structured data without manually sifting through pages, which saves time and resources.
For example, a Facebook data scraper can collect all comments on a product review or extract contact information from business pages for lead generation. It automates the process, making it faster and more scalable, which is essential for businesses that need to monitor large amounts of data.
Facebook isn’t just cat videos and memes—it’s a $42B+ treasure trove of consumer insights, competitor moves, and market trends. But manually collecting this data? That’s like using a teaspoon to empty an ocean. A Facebook data scraper automates this process, letting you:
Track competitors’ ad strategies in real time.
Analyze customer sentiment from millions of posts/comments.
Build hyper-targeted lead lists from business pages.
Case Study: A skincare brand scraped 10k+ beauty group posts, identified a surge in “clean ingredient” demand, and launched a best-selling product line in 3 months.
So, how does a Facebook data scraper work? While the exact process may vary slightly depending on the tool you’re using, here’s the general flow:
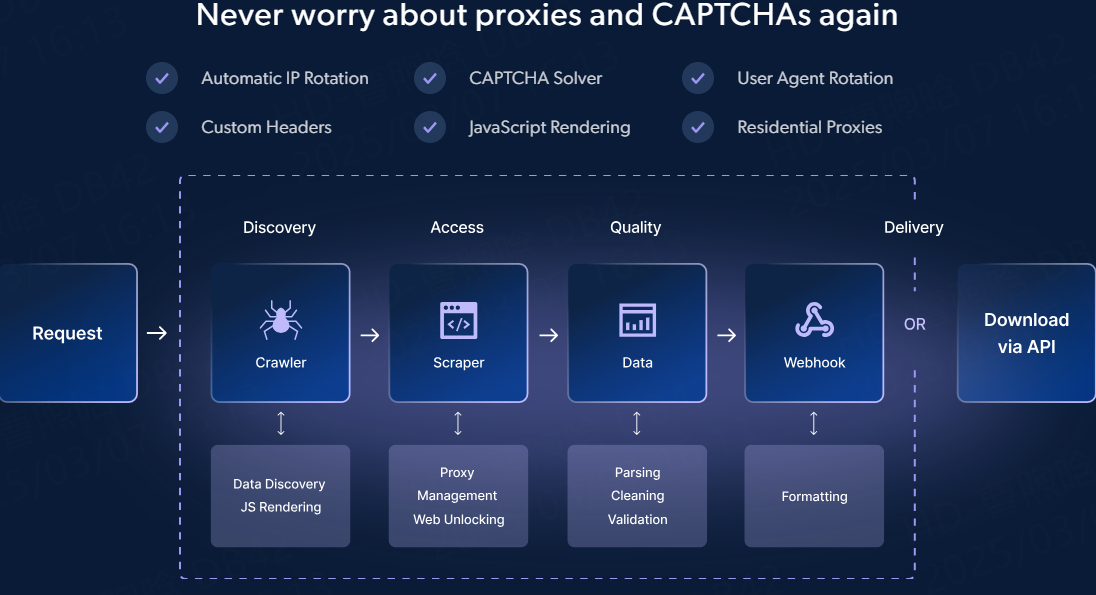
1. Target URLs
Input Facebook pages/groups (e.g., competitor profiles).
2. Select Data
Choose posts, comments, likes, shares, or profiles.
3. Scrape & Export
Get structured CSV/JSON files in minutes.Once the data has been scraped, you can export it in a usable format such as CSV, Excel, or JSON. This makes it easy to analyze, store, or integrate with your other tools and systems.
import requests
from bs4 import BeautifulSoup
proxies = {
‘http’: ‘http://user:pass@residential.thordata.com:3000’,
‘https’: ‘http://user:pass@residential.thordata.com:3000’
}
url = ‘https://facebook.com/competitor-page’
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64)’}
response = requests.get(url, proxies=proxies, headers=headers)
soup = BeautifulSoup(response.text, ‘html.parser’)
posts = [post.text for post in soup.select(‘.userContent’)]
The ability to automate data collection from Facebook can open up numerous benefits for your business. Here’s how using a Facebook data scraper can help you gain a competitive edge:
One of the main advantages of using a Facebook data scraper is scalability. While it’s easy to collect data from a few pages or posts manually, scraping tools can help you gather data from hundreds or even thousands of profiles in a matter of minutes. This is especially useful for market research, sentiment analysis, and competitive intelligence.
A Facebook data scraper can help you target specific customer segments. For instance, by scraping posts that mention certain keywords related to your product or service, you can identify potential customers who are already interested in your industry. These insights allow you to create more targeted and personalized marketing campaigns.
With the data collected from Facebook, businesses can make more informed decisions. Whether it’s deciding on which products to feature or analyzing customer feedback to improve customer service, having access to real-time, accurate data means you can always stay one step ahead of the competition.
Facebook is a powerful tool for understanding customer sentiment. By scraping posts and comments related to your brand or industry, you can track how people feel about your products, services, or even your competitors. This data can inform your strategies and help improve customer relationships.
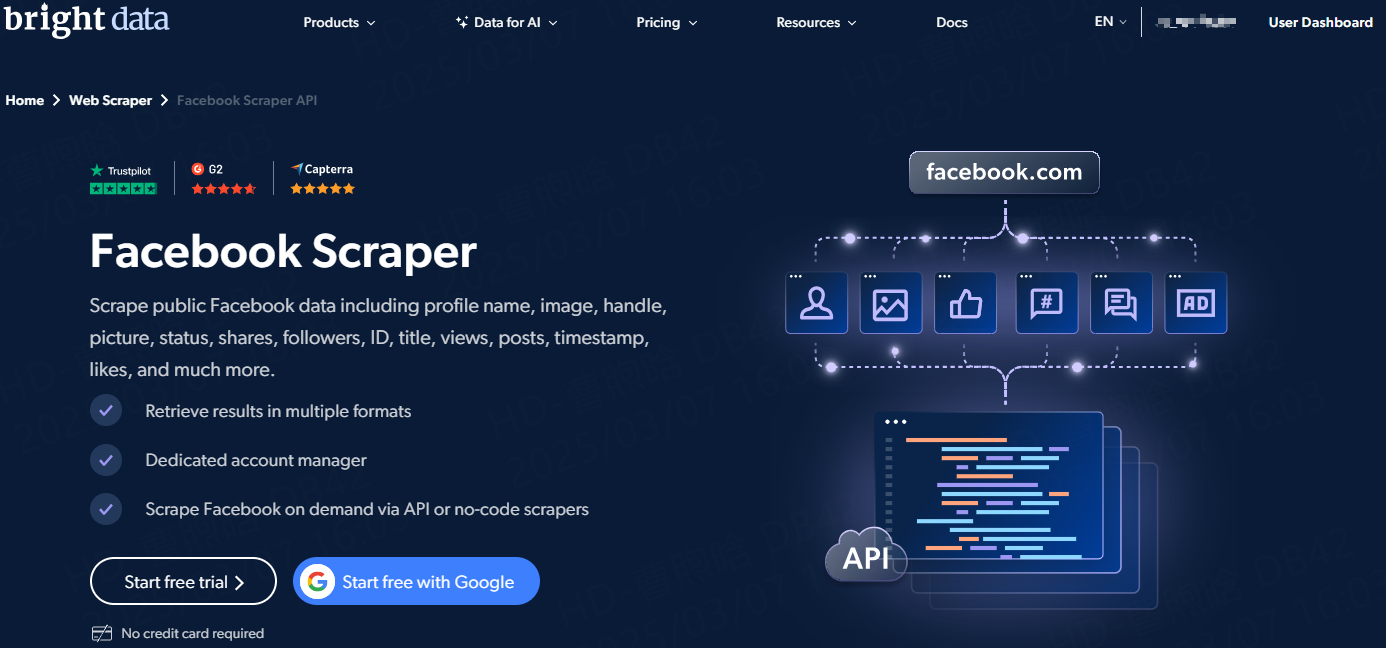
Scrape public Facebook data, including profile name, image, handle, picture, status, shares, followers, ID, title, views, posts, timestamp, likes, and much more.
Retrieve results in multiple formats
Dedicated Account Manager
Scrape Facebook on demand via API or no-code scraper.
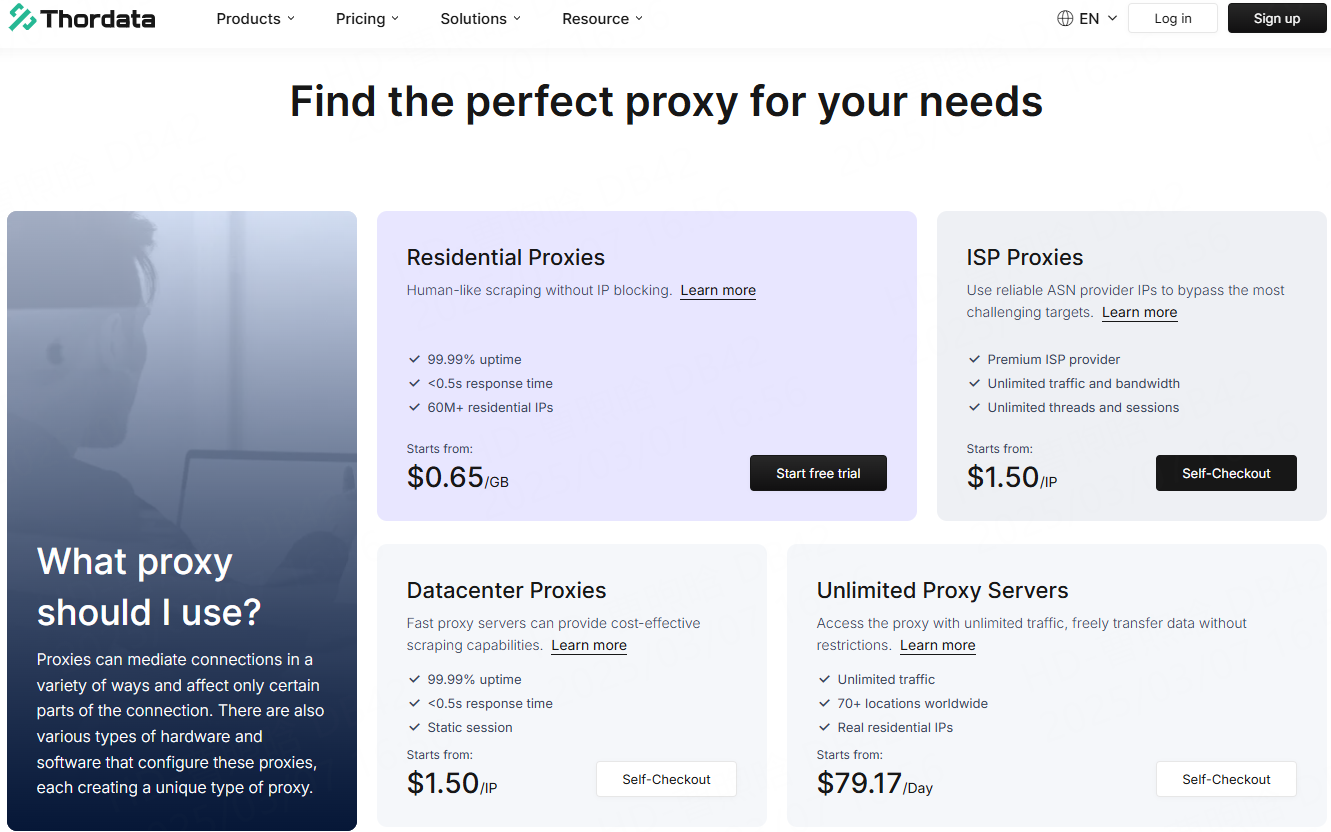
Military-Grade Encryption: AES-256 for data in transit/rest.
Global IP Network: 60M+ IPs across 190 countries.
Zero Logs: No activity records—ever.
Case Study: An e-commerce firm scraped 50k product reviews using Thordata. Result? Zero blocks, 40% faster than competitors.
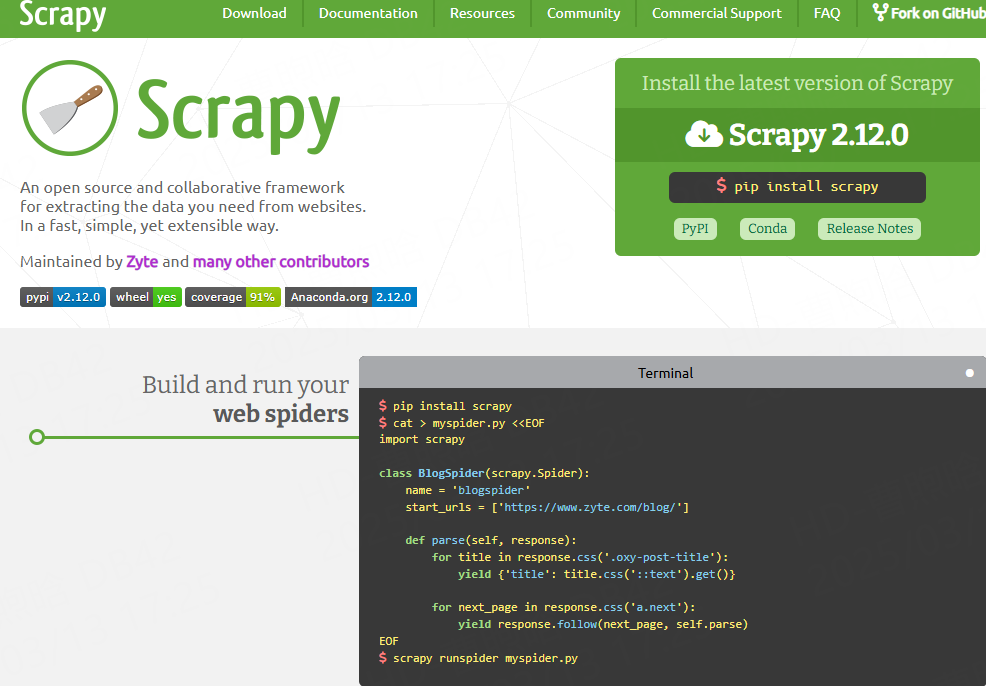
Scrapy is a powerful Python framework that is ideal for technical users and developers.
Customizable: Tailor scraping tasks to your specific needs.
Scalable: Efficiently manages large-scale scraping projects.
Fast: High-speed data extraction capabilities.
Best For: Developers requiring flexibility and power in their scraping projects.
Understanding the legal landscape of Facebook scraping is crucial:
Facebook’s terms of service explicitly prohibit unauthorized data scraping. Violating these terms can lead to account suspension, legal action, or other penalties.
Legal perspectives on scraping vary by location. While scraping public data might be permitted in some areas, Facebook’s terms of service still apply.
Extracting personal data without consent may violate privacy laws, which can be illegal in many jurisdictions.
To get the most out of your Facebook data scraper, you need to ensure that your scraping process is seamless and uninterrupted. Thordata’s proxy services provide the perfect solution to this problem. With rotating IPs and reliable, fast proxies, Thordata ensures that your Facebook data scraper will run smoothly without any interruptions or IP bans. This means you can scrape large amounts of data safely and efficiently without worrying about running into obstacles.
Thordata’s proxies help you maintain anonymity, avoid throttling, and ensure compliance with Facebook’s scraping policies. So, if you’re looking for a reliable, secure way to extract data from Facebook, Thordata’s proxy services are the perfect complement to your Facebook data scraper.
Frequently asked questions
Can I scrape Facebook without coding?
Yes! Tools like Octoparse offer no-code templates.
How to avoid legal trouble with Facebook scraping?
Only scrape public data, use ethical tools, and consult legal counsel.
Why does my scraper get blocked instantly?
You’re likely using datacenter IPs. Switch to Thordata’s residential proxies.
About the author
Jenny is a Content Specialist with a deep passion for digital technology and its impact on business growth. She has an eye for detail and a knack for creatively crafting insightful, results-focused content that educates and inspires. Her expertise lies in helping businesses and individuals navigate the ever-changing digital landscape.
The thordata Blog offers all its content in its original form and solely for informational intent. We do not offer any guarantees regarding the information found on the thordata Blog or any external sites that it may direct you to. It is essential that you seek legal counsel and thoroughly examine the specific terms of service of any website before engaging in any scraping endeavors, or obtain a scraping permit if required.
 Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
AI Data Collection: How to Source, Prepare, and Use Data for Smarter AI
Artificial intelligence is onl ...
ning loop. Xyla Huxley
2026-06-24

Proxy vs Firewall: What’s the Difference?
Firewalls and proxies are used ...
Kael Odin
2026-06-23

Building a Real-Time Sports Video Pipeline That Feeds Your LLM Without Getting Cut Off
You need fresh sports video in ...
Xyla Huxley
2026-06-23

The Quiet Revolution: How Sports Video Is Reshaping Multimodal LLM Training Methodologies
The academic community spent a ...
Xyla Huxley
2026-06-23

The $400K Mistake: Thinking AI Model Training for Sports Video Only Needed GPUs
We approved the budget in Janu ...
Xyla Huxley
2026-06-23

Why Your LLM’s Sports Video Understanding Depends on Residential Proxy Infrastructure You Haven’t Built Yet
You spent six months optimizing your LLM’s transf […]
Unknown
2026-06-23

How to Create Original Facebook Ad Creatives and Reduce Rejection Risk
Learn how to create original F ...
Jenny Avery
2026-06-22

Training a Cooking Robot? Your YouTube Data Pipeline Needs to See Every Kitchen in the World
Robotics companies training vi ...
Xyla Huxley
2026-06-18

YouTube Video Collection at Scale: A Complete Python Pipeline with Residential Proxy Integration
This is a practical guide for ...
Xyla Huxley
2026-06-18
