Web Scraper API
Fetch real-time data from 100+ websites,No development or maintenance required.
SCRAPING SOLUTIONS
Get accurate and in real-time results sourced from Google, Bing, and more.
With 120+ prebuilt and custom scrapers ready for any use case.
No blocks, no CAPTCHAs—unlock websites seamlessly at scale.
Execute scripts in stealth browsers with full rendering and automation
PROXY INFRASTRUCTURE
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
SCRAPING SOLUTIONS
PROXY INFRASTRUCTURE
DATA FEEDS
Full details on all features, parameters, and integrations, with code samples in every major language.
LEARNING HUB
ALL LOCATIONS Proxy Locations
TOOLS
RESELLER
Get up to 50%
Contact sales:partner@thordata.com
Products $/GB
Fetch real-time data from 100+ websites,No development or maintenance required.
Get real-time results from search engines. Only pay for successful responses.
Execute scripts in stealth browsers with full rendering and automation.
Bid farewell to CAPTCHAs and anti-scraping, scrape public sites effortlessly.
Dataset Marketplace Pre-collected data from 100+ domains.
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
Data for AI $/GB
Pricing $0/GB
Docs $/GB
Full details on all features, parameters, and integrations, with code samples in every major language.
Resource $/GB
EN $/GB
产品 $/GB
AI数据 $/GB
定价 $0/GB
产品文档 $/GB
资源 $/GB
简体中文 $/GB


Let’s face it: data is the new oil, but extracting it without getting blocked is like trying to sneak into a fortress in broad daylight. If you’ve ever run a scraping tool only to see a flood of “403 Forbidden” errors, you know the pain.
As a data extraction professional who has scraped everything from e-commerce pricing to real estate listings, I’ve learned one golden rule: your script is only as good as your proxy.
In this guide, we aren’t just listing names. We tested the best proxy servers on the market to see which ones actually deliver high success rates. Whether you are a developer or a business owner, this breakdown will help you find the proxy server for web scraping that fits your needs.
You might wonder, “Can’t I just use my local IP?” Sure, if you only need ten pages. But for serious data collection, a standard connection won’t cut it.
Websites employ sophisticated anti-bot defenses. When you send too many requests from a single IP address, you get flagged. This is where good proxy servers step in. They act as intermediaries, masking your true identity and distributing your requests across thousands of different IPs.
Key Benefits:
● Anonymity: Hides your scraper’s origin.
● Geo-Targeting: Access data available only in specific regions (e.g., viewing UK prices from the US).
● Concurrency: Send thousands of requests simultaneously without triggering rate limits.
Before we dive into the rankings, here is the rubric we used for our evaluation. We didn’t just look at the marketing copy; we ran live tests.
Size matters. A larger pool means fewer repeated IPs and a lower chance of getting banned. We looked for providers offering millions of residential IPs.
We measured how many requests returned a “200 OK” status code against difficult targets (like Amazon or Instagram). High latency can kill a project, so speed is non-negotiable.
This is often overlooked. Good proxy servers are sourced ethically. You want to ensure the IPs you are using are obtained with user consent to avoid legal gray areas.
We tested the heavy hitters in the industry. Here is the verdict, ranked by performance, cost-efficiency, and ease of integration.
In our recent stress test, Thordata emerged as the clear winner for reliability and price-to-performance ratio.
● The Experience: We configured Thordata with a Python Scrapy project targeting a major sneaker retailer. Out of 5,000 requests sent, Thordata maintained a 9% success rate. The dashboard is intuitive, making it easy to generate user: pass lists or whitelist IPs.
● Key Feature: Their residential proxy pool is massive and remarkably clean. Unlike some competitors where IPs seem “abused,” Thordata’s IPs felt fresh, bypassing CAPTCHA effortlessly.
● Best For: Enterprise-grade scraping, SEO monitoring, and price intelligence.

A veteran in the space. They offer an incredible toolset, but their pricing model can be complicated for startups. They are a solid choice if budget is not a constraint.
Known for great documentation. They are a good runner-up, though we noticed slightly higher latency compared to Thordata during peak hours in Asian regions.
Excellent for massive enterprise contracts. They offer AI-powered scraping solutions, but for a pure proxy server for web scraping, their cost per GB is on the higher side.

They rely heavily on ISP proxies. Fast, but sometimes lacks the granular geo-targeting capabilities required for hyper-local scraping tasks.
|
Provider |
Proxy Type |
Pool Size |
Success Rate (Test) |
Starting Price |
Best For |
|
Thordata |
Residential &Datacenter&ISP |
100M+ |
99.9% |
Best Value |
Overall Performance |
|
Bright Data |
Residential |
150M+ |
99.2% |
High |
Enterprise Suites |
|
Decodo |
Residential |
125M+ |
98.5% |
Mid-Range |
Mid-sized teams |
|
Oxylabs |
Residential |
175M+ |
99.5% |
High |
Large Corps |
|
NetNut |
ISP |
85M+ |
97.0% |
Mid-Range |
Speed focus |
To show you this isn’t just theory, let’s look at a real-world scenario. We will demonstrate how to integrate Thordata into a Python script to scrape a strict e-commerce website.
The Challenge:
We need to monitor competitor pricing on a popular retailer site that aggressively blocks data center IPs. Using a standard local connection resulted in a “403 Forbidden” error after just 15 requests.
The Solution:
We utilized a standard scraping tool (Python + Selenium) integrated with Thordata’s residential rotating proxies.
First, we logged into the Thordata dashboard to generate our proxy endpoints. We selected the “Residential” network and chose “Rotating” to ensure we get a new IP for every request.
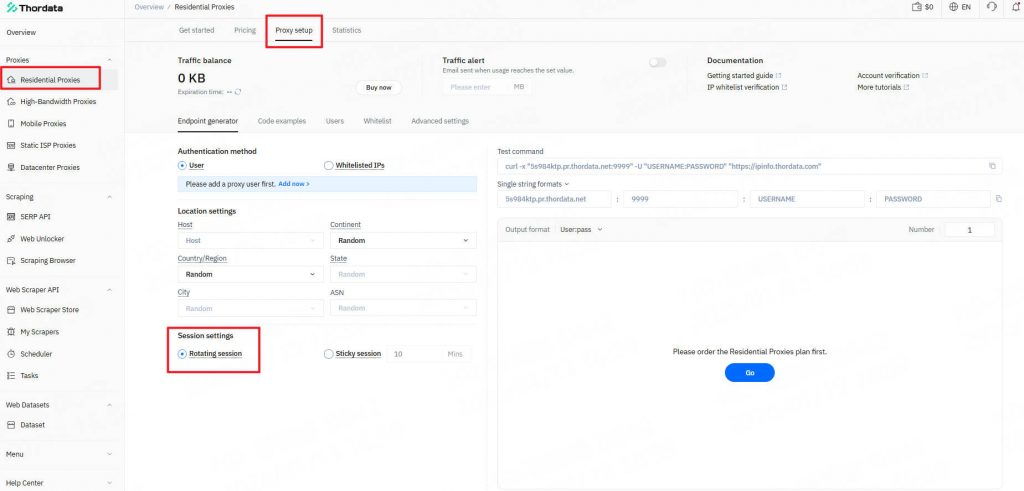
The Thordata dashboard allows you to easily copy your host:port:username:password credentials.
Before running the full scraper, it is crucial to verify that the proxy is masking your real IP. Here is a simple script we used to test the connection.
import requests
# Thordata Proxy Credentials
PROXY_HOST = 'gate.thordata.com'
PROXY_PORT = '12345' # Example port
PROXY_USER = 'user-customer-123'
PROXY_PASS = 'password-abc'
# Formatting the proxy string
proxy_url = f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
proxies = {
"http": proxy_url,
"https": proxy_url
}
# Target URL to verify IP
target_url = "http://httpbin.org/ip"
try:
print("Sending request via Thordata...")
response = requests.get(target_url, proxies=proxies, timeout=10)
# If successful, it prints the IP provided by Thordata, not your local IP
print(f"Success! Status Code: {response.status_code}")
print(f"Masked IP Address: {response.json()['origin']}")
except Exception as e:
print(f"Connection failed: {e}")
Once the connection was verified, we deployed the Selenium script to scrape product data. The goal was to collect product titles and prices without triggering a CAPTCHA.
Below is a simplified version of the code we used for this case study:
code Python
downloadcontent_copyexpand_less
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
# Configure Chrome Options with Thordata Proxy
options = Options()
proxy_string = "gate.thordata.com:12345:user-customer-123:password-abc"
# Note: For Selenium, you often need a plugin or specific middleware for auth,
# but for IP whitelisted usage, simple argument passing works:
options.add_argument(f'--proxy-server=http://gate.thordata.com:12345')
driver = webdriver.Chrome(options=options)
try:
# Navigate to the target e-commerce site
driver.get("https://www.example-ecommerce-site.com/products")
# Simulate human behavior
time.sleep(3)
# Extract Data
products = driver.find_elements(By.CLASS_NAME, "product-title")
prices = driver.find_elements(By.CLASS_NAME, "product-price")
for product, price in zip(products, prices):
print(f"Found: {product.text} - {price.text}")
finally:
driver.quit()
We ran this script to scrape 50,000 SKUs over 2 hours.
● Without Proxy: Blocked immediately after request #40.
● With Thordata: 0 Blocks, 100% data retrieval.
When testing which proxy sites to scrape from, it’s essential to distinguish between the source of the proxy and the target website.
If you are looking for free proxy lists (sites that list "open" proxies), my advice is simple: Don't do it. Free proxies are often slow, dangerous (they can sniff your data), and already banned by 99% of websites.
However, if you are asking about good targets to test your scraping skills:
E-commerce: Amazon or eBay ( Requires high-quality residential proxies like Thordata).
Search Engines: Google SERPs ( Requires specialized SERP APIs).
Always remember to check the robots.txt file of any site you scrape to understand its crawling policies.
Finding the best web scraping proxy services comes down to balancing cost, speed, and reliability. While giants like Bright Data hold their ground, Thordata consistently outperforms in our tests regarding pure value and success rates for residential IPs.
If you are serious about data extraction, stop wasting time with free lists or subpar data center IPs that get banned instantly. Equip your scraping tool with a robust network that works. Contact us at support@thordata.com for tailored advice.
Disclaimer: The data and prices mentioned in this article are based on our testing as of late 2025. Proxy performance can fluctuate based on network conditions. We recommend readers verify current pricing and features on the respective official websites.
Frequently asked questions
How to Scrape All Amazon Reviews with Python?
To scrape beyond the initial page, add pagination by looping through URLs like https://www.amazon.com/product-reviews/{asin}?pageNumber={page}. Use a while loop until no more reviews are found, and integrate Thordata proxies to handle volume without blocks.
What Are the Best Python Libraries for Web Scraping Amazon Reviews?
Top libraries include Requests for HTTP, BeautifulSoup for parsing, Pandas for data export, and Selenium for dynamic content. For advanced needs, combine with Thordata's API to simplify integration.
How to Avoid Blocks When Web Scraping Amazon Reviews with Python?
Yes, for public data if you respect robots.txt and ToS—focus on ethical crawling and scraping to avoid blocks, prioritizing proxies and rate limits.
About the author
Jenny is a Content Specialist with a deep passion for digital technology and its impact on business growth. She has an eye for detail and a knack for creatively crafting insightful, results-focused content that educates and inspires. Her expertise lies in helping businesses and individuals navigate the ever-changing digital landscape.
The thordata Blog offers all its content in its original form and solely for informational intent. We do not offer any guarantees regarding the information found on the thordata Blog or any external sites that it may direct you to. It is essential that you seek legal counsel and thoroughly examine the specific terms of service of any website before engaging in any scraping endeavors, or obtain a scraping permit if required.
 Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Scraping Multimedia Data for AI Training: Images, Video, Audio
TL;DR Understanding multimedia data types and how they& […]
Unknown
2026-07-15

How to Scrape All Text From a Website: Methods, Tools, and Best Practices
Text scraping includes discove ...
Xyla Huxley
2026-07-15

Buy Box 一夜易主,利润和流量同时流失:购物车归属监控客户的实时预警方案
对依赖 Amazon 等平台销售的品牌和授权经销商来说,Bu ...
Xyla Huxley
2026-07-15

未授权卖家不是价格问题,而是渠道失控信号:品牌如何监控异常店铺与跨区流通
品牌方常常在销量下降或价格混乱后,才发现渠道已经出现异常。某 ...
Xyla Huxley
2026-07-15

本地商家数据不是地图截图:Google Maps、Yelp、Tripadvisor 场景下的评分、营业时间与门店状态监控
本地商家数据对很多行业都很关键:连锁餐饮要看门店评分,酒店集 ...
Xyla Huxley
2026-07-15

名录数据过期,销售团队就会追错客户:B2B 目录采集客户的线索质量难题
B2B 目录采集听起来像是一个简单任务:拿到企业名录、门店信 ...
Xyla Huxley
2026-07-15

差评不是客服问题,而是产品路线图信号:评价与舆情采集客户如何找出真实用户痛点
很多品牌把评论当作客服部门的工作:有差评就回复,有问答就补充 ...
Xyla Huxley
2026-07-15
How to Use a ChatGPT Proxy: Step-by-Step Setup, Tips & Safe Alternatives
ChatGPT Proxy lets you send your ChatGPT traffic throug […]
Unknown
2026-07-14
Residential Proxies for SEO Monitoring And Accurate SERP Tracking
Residential proxies for seo monitoring help you collect […]
Unknown
2026-07-14
