Web Scraper API
Fetch real-time data from 100+ websites,No development or maintenance required.
SCRAPING SOLUTIONS
Get accurate and in real-time results sourced from Google, Bing, and more.
With 120+ prebuilt and custom scrapers ready for any use case.
No blocks, no CAPTCHAs—unlock websites seamlessly at scale.
Execute scripts in stealth browsers with full rendering and automation
PROXY INFRASTRUCTURE
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
SCRAPING SOLUTIONS
PROXY INFRASTRUCTURE
DATA FEEDS
Full details on all features, parameters, and integrations, with code samples in every major language.
LEARNING HUB
ALL LOCATIONS Proxy Locations
TOOLS
RESELLER
Get up to 50%
Contact sales:partner@thordata.com
Products $/GB
Fetch real-time data from 100+ websites,No development or maintenance required.
Get real-time results from search engines. Only pay for successful responses.
Execute scripts in stealth browsers with full rendering and automation.
Bid farewell to CAPTCHAs and anti-scraping, scrape public sites effortlessly.
Dataset Marketplace Pre-collected data from 100+ domains.
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
Data for AI $/GB
Pricing $0/GB
Docs $/GB
Full details on all features, parameters, and integrations, with code samples in every major language.
Resource $/GB
EN $/GB
产品 $/GB
AI数据 $/GB
定价 $0/GB
产品文档 $/GB
资源 $/GB
简体中文 $/GB
<–!>
<–!>

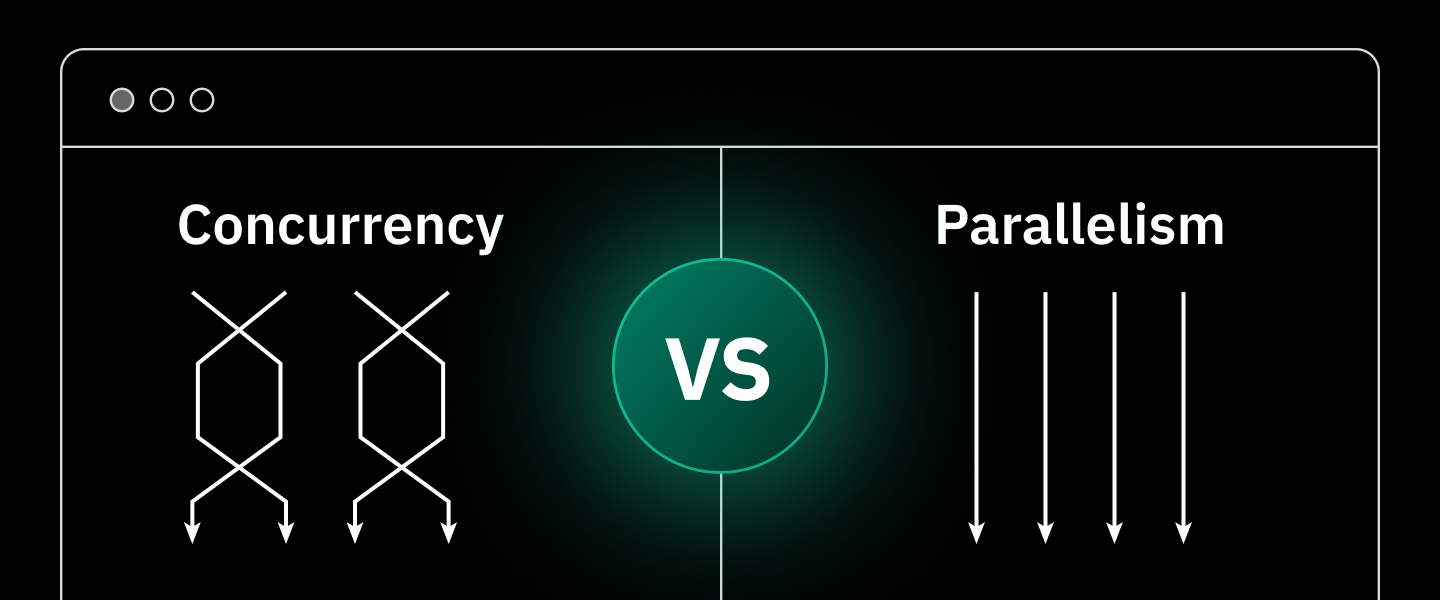
If you have delved deeply into Python programming or high-concurrency system architecture, you may have pondered late into the night about how to make tasks run faster. Although Python offers powerful libraries to address execution efficiency issues, the terms concurrency and parallelism are often confused. This article will delve into the core definitions and key differences between concurrency and parallelism, and ultimately explore how they work together in real-world applications such as web scraping.
Concurrency is essentially the ability to handle multiple tasks, which does not mean these tasks run simultaneously within the same second. It focuses on structure—the system is designed to handle multiple task flows. A concurrent system can start, run, and complete multiple programs during overlapping time periods by switching context. As the Association for Computing Machinery (ACM) pointed out in its white paper on computing system architecture: “Concurrency is an attribute of properly handling various independent activities that occur simultaneously.”
Imagine a web server that needs to handle multiple user requests. It cannot physically handle all requests at once, but it can manage them efficiently through concurrency.
• User A requests the homepage.
• User B submits a login form.
• User C queries the product list.
The concurrent workflow for the server handling these requests does not execute simultaneously but rotates quickly.
1. The system receives independent data requests from three users.
2. The server scheduler allocates CPU time to the first user’s request for initial processing.
3. When the first request encounters network delays or database queries, it is temporarily suspended by the system.
4. The scheduler quickly switches to the second user’s task and begins computation using available CPU cycles.
5. The third task is inserted into the execution sequence during the gap while waiting for the first two tasks to release resources.
6. The system continues to cycle through multiple incomplete tasks until all logical loops are closed.
• High-concurrency web servers: such as Nginx, handling thousands of concurrent connections.
• Graphical user interfaces: maintaining UI responsiveness while executing tasks in the background.
• Real-time systems: monitoring multiple input sources and responding in a timely manner.
• I/O-intensive applications: such as file reading and writing, network communication, etc.
Nowadays, developers have introduced various concurrency models to compensate for the shortcomings of single-threaded processing in handling I/O-intensive tasks, the following are the mainstream concurrency models and examples:
In this model, multiple threads share the same process memory space, managed by the operating system’s kernel for scheduling and switching. This is the most traditional way to achieve concurrency, suitable for I/O-intensive tasks. However, due to shared memory, careful attention must be paid to thread safety issues, such as race conditions.
Examples:
• Web server backends (like Java Tomcat).
• Desktop applications (like the background spell check in Microsoft Word).
• Database connection pools.
This model revolves around a core event loop; when a task needs to wait (such as for I/O), it suspends and registers a callback, then immediately processes other ready tasks. Once the wait is complete, the callback is triggered. This avoids thread blocking and switching overhead, resulting in high performance.
Examples:
• Node.js servers.
• Nginx web servers.
• Python’s asyncio framework.
Coroutines are lighter-weight user-space “micro-threads” compared to threads, with switching points explicitly controlled by the programmer in the code (yield, async/await). It combines the high concurrency of multithreading with the efficiency of event-driven models, showing a very high energy efficiency ratio when handling large-scale concurrent I/O (such as web scraping).
Examples:
• Go’s Goroutines.
• Python’s asyncio coroutines.
• Lua’s coroutines.
Parallelism describes a state of execution where multiple tasks are executed simultaneously at the exact same moment. This requires support from multi-core processors or clusters of multiple computers. Intel clearly states in its “Parallel Programming Books“: “Parallelism is the simultaneous execution of multiple computations using multi-core hardware to shorten the total time required to solve complex problems.” Parallelism focuses on execution—utilizing multiple resources to work simultaneously, just like having several chefs, each responsible for one pot, truly cooking at the same time.
A video editing software needs to apply complex filters to each frame of a 4K video.
1. The video data is loaded into memory.
2. The system divides the video frame sequence into four equal groups.
3. Four CPU cores start simultaneously, with each core independently processing the filter calculations for one group of frames.
4. After all cores have finished processing, the results are gathered and saved.
In this process, tasks are physically split and processed simultaneously by independent execution units, significantly reducing the overall time.
• Scientific computing and simulations: such as climate modeling, physical modeling.
• Machine learning training: parallel gradient calculations across multiple GPUs.
• Big data processing: using Hadoop/Spark for MapReduce.
• 3D graphics rendering: parallel rendering by dividing the scene into chunks.
• Password cracking: simultaneously attempting a large number of key combinations.
In order to achieve true synchronous execution at the hardware level, various models of parallel computing have been developed to maximize the utilization of computational resources.
This model achieves parallelism by creating multiple independent operating system processes. Each process has its own memory space and does not interfere with others, exchanging data through inter-process communication. This avoids thread safety issues, but comes with higher overhead for creation and communication.
Examples:
• The prefork mode of the Apache web server.
• Python’s multiprocessing module (used to bypass the GIL).
• Google Chrome browser (one process per tab).
This model allows a single instruction to operate on multiple data elements simultaneously, greatly enhancing the efficiency of vector computations. It’s like an automated production line where a single action processes a row of products at the same time.
Examples:
• GPU rendering pipeline
• Image and signal processing
• Intel SSE/AVX instruction sets
This is the most general parallel model, where each processor can execute different instruction streams to handle different data streams. Most modern multi-core computing systems fall under this architecture.
Examples:
• Multi-core distributed systems
• Supercomputer clusters
• Multiprocessor workstations
When delving into concurrent vs parallel, you may inevitably encounter some dizzying underlying terms. I have also been troubled by these terms for a long time. To help you avoid making the same mistakes, I have organized the following comparison table of core terms:
| Term | Overview |
| Thread | The smallest unit of scheduling that an operating system can perform, contained within a process. |
| Single-threaded | The program executes line by line in code order and can only handle one logical flow at a time. |
| Multi-threaded | Multiple threads are launched simultaneously within a process, utilizing concurrency or parallelism to improve efficiency. |
| Asynchronous | After making a call, it does not wait for the result, directly continuing to execute subsequent operations, with results provided through callbacks or status notifications. |
| Synchronous | The program must wait for the current operation to complete before it can continue executing the next instructions. |
Now, we have enough background knowledge to directly compare this pair of core concepts. While both aim to improve program performance, their focus is completely different.
Concurrency is about handling many things at the same time, whereas parallelism is about doing many things simultaneously. — Rob Pike, co-founder of Go language
This succinct summary captures the essence: concurrency is the abstraction of the problem domain (how to manage multiple tasks), while parallelism is the concretization of the solution domain (how to execute multiple tasks).
• Concurrency aims to maximize CPU utilization through efficient task scheduling, especially in scenarios with a high amount of I/O waiting.
• Parallelism aims to minimize total task execution time by increasing computational resources, suitable for compute-intensive scenarios.
• Concurrency can be achieved on a single CPU core via time-slicing.
• Parallelism must rely on multiple CPU cores or processors.
• Concurrency tasks often have interactions and dependencies, requiring communication and coordination.
• Parallel tasks can be designed to be highly independent, processing different data shards.
• Concurrency is primarily a matter of software design and architecture.
• Parallelism is more dependent on hardware architecture and resources.
In Python, the Global Interpreter Lock (GIL) is an important feature that prevents multiple native threads from executing Python bytecode simultaneously, which limits the parallelism of multithreading in CPU-intensive tasks. Therefore, Python developers often need to combine concurrency and parallelism models to unlock performance.
A typical scenario is building a data pipeline: data needs to be fetched concurrently from multiple API sources (I/O-intensive), and then the large amount of data obtained is cleaned and processed in parallel (CPU-intensive).
The concurrent.futures module provides a high-level interface, allowing us to conveniently combine ThreadPoolExecutor (for I/O concurrency) and ProcessPoolExecutor (for CPU parallelism).
python
import concurrent.futures
import requests
import hashlib
# Simulate I/O intensive tasks: concurrently fetching webpage content
urls = ['https://api.example.com/data1', 'https://api.example.com/data2', 'https://api.example.com/data3']
def fetch_url(url):
response = requests.get(url)
return response.content
# Simulate CPU intensive tasks: parallel computing data hashes
def compute_hash(data):
return hashlib.sha256(data).hexdigest()
def main():
all_hashes = []
# Step 1: Use a thread pool to concurrently execute web requests (I/O intensive)
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as io_executor:
future_to_url = {io_executor.submit(fetch_url, url): url for url in urls}
fetched_data = []
for future in concurrent.futures.as_completed(future_to_url):
data = future.result()
fetched_data.append(data)
# Step 2: Use a process pool to parallel compute hashes (CPU intensive, can bypass GIL)
with concurrent.futures.ProcessPoolExecutor() as cpu_executor:
hash_futures = [cpu_executor.submit(compute_hash, data) for data in fetched_data]
for future in concurrent.futures.as_completed(hash_futures):
hash_result = future.result()
all_hashes.append(hash_result)
print(f"Hashes of all data: {all_hashes}")
if __name__ == '__main__':
main()
1. Large-Scale Distributed Web Scraper
A modern web scraping system must be efficient, robust, and scalable.
• Use concurrency models (such as asynchronous I/O) to manage thousands of simultaneous network requests and connections.
• Parallelly allocate the URLs to be scraped to multiple crawling worker nodes (which may be multiple machines or multiple processes).
• Within each worker node, use concurrency to handle the download, parsing, and data extraction pipelines for multiple pages.
• Parallelly send the extracted raw data to back-end storage or processing clusters.
• To circumvent anti-scraping strategies, the entire system needs to integrate reliable web scraping proxy services that intelligently rotate IPs.
2. Real-Time Financial Trading Analysis Platform
Such platforms need to process massive amounts of market data and make decisions in a very short amount of time.
• Concurrently receive real-time data streams from multiple exchanges.
• Parallelly process pricing model calculations for different financial instruments (stocks, options, futures).
• Concurrently execute risk checks and compliance monitoring.
• Parallelly backtest the performance of new trading algorithms on historical data.
• Combine concurrency in generating trading signals with parallel optimization of investment portfolios.
3. Cloud-Native Microservices E-commerce System
A typical e-commerce backend consists of dozens of microservices that need to handle high-concurrency user requests.
• Each microservice instance internally uses concurrency (multithreading/asynchronous) to handle multiple user requests.
• Parallelly distribute user traffic to multiple running instances of the same service through a load balancer.
• Perform concurrent asynchronous communication between order services, inventory services, payment services, etc.
• The recommendation engine parallelly computes personalized product lists for different users.
• The logging and metrics collection system concurrently receives data and performs parallel aggregation analysis.
When we turn our attention to the field of web scraping, the value of concurrency and parallelism is maximally demonstrated. Traditional single-threaded crawling is not only inefficient but also easily triggers a website's anti-scraping mechanisms, resulting in your IP being banned. To bypass these limitations, modern developers often combine high-performance proxy servers, simulating real user behavior through a large number of concurrent requests from different geographic locations. However, managing complex proxy pools and dealing with JavaScript dynamic rendering remain significant challenges.
If you want to directly obtain structured data, choosing Thordata's public data collection solution—Web Scraper API—is a wiser approach. These APIs already integrate advanced concurrency scheduling algorithms internally, automatically configuring high-performance residential proxies for you. In this way, you can leverage the massive distributed resources provided by the service provider to achieve true parallel scraping without worrying about the instability and low success rates that cheap proxies may bring. For teams that wish to focus more on business logic rather than underlying architecture, there is a free trial available to see if it can meet their business needs.
Through this in-depth analysis, we can easily see that concurrency vs parallelism is not a battle of who replaces whom, but rather a collaboration focused on resource optimization. Concurrency gives us the flexibility to handle multi-task interactions, while parallelism provides the hard capability to crush large-scale computations. When building modern high-performance systems, how to balance the use of these two based on the business characteristics (whether I/O-intensive or CPU-intensive) will directly determine the vitality of your code. In this data-driven era, mastering these core differences and skillfully using web scraping technology will give you a significant competitive advantage in your technical development journey.
Learn more comparison articles, such as HTTPX vs Requests vs AIOHTTP, Web Crawler vs Web Scraper, Go vs Python.
We hope the information provided is helpful. However, if you have any further questions, feel free to contact us at support@thordata.com or via online chat.
<--!>
Frequently asked questions
What is an example of a concurrency?
Concurrency refers to multiple tasks being processed alternately within the same time frame. A classic example is a restaurant waiter: while waiting for the food at table A, the waiter might pour water for table B or take payment for table C. Although only one task is being done at any moment, on a larger scale, multiple orders are being progressed through rapid task switching.
Is multithreading concurrent or parallel?
Multithreading can be either concurrent or parallel, depending on the hardware environment. On a single-core CPU, multithreading is executed by time-slicing, which is considered concurrency; whereas on a multi-core CPU, multiple threads can be assigned to different cores to run simultaneously, thus achieving true parallelism.
Can you have concurrency without parallelism?
Yes, you can have concurrency without parallelism. Concurrency is about the logical organization of tasks (how to manage multiple tasks), while parallelism is about physical execution (whether tasks are running simultaneously). For example, a single-core CPU achieves concurrent processing by rapidly switching between multiple tasks, but can only execute one task at any given moment, so there is no parallelism.
What is the difference between concurrency and parallelism in go?
In Go, concurrency is the logical structure of a program, where tasks are split into independent units using Goroutines, focusing on task management; parallelism is the physical execution state, referring to these tasks running simultaneously on a multi-core CPU. As the founder of Go said: concurrency is about "dealing with" many things, while parallelism is about "doing" many things at the same time.
<--!>
About the author
Anna is a content specialist who thrives on bringing ideas to life through engaging and impactful storytelling. Passionate about digital trends, she specializes in transforming complex concepts into content that resonates with diverse audiences. Beyond her work, Anna loves exploring new creative passions and keeping pace with the evolving digital landscape.
The thordata Blog offers all its content in its original form and solely for informational intent. We do not offer any guarantees regarding the information found on the thordata Blog or any external sites that it may direct you to. It is essential that you seek legal counsel and thoroughly examine the specific terms of service of any website before engaging in any scraping endeavors, or obtain a scraping permit if required.
 Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
How to Download Sports Highlights at Scale Using Residential Proxies (Python Guide)
Build a production-ready sports video downloader that h […]
Unknown
2026-06-12

Why Your Sports Video Downloader Keeps Getting Blocked (And How Residential Proxies Fix It)
The real reason your Python scripts fail—and the infras […]
Unknown
2026-06-12

Building an Automated Sports Video Pipeline: From Discovery to Download with Smart Proxies
How to build a zero-touch system that finds, validates, […]
Unknown
2026-06-12

The Complete Guide to Scraping and Downloading Sports Videos Without IP Bans
Understanding the Landscape Sports video content exists […]
Unknown
2026-06-12

World Cup 2026 Is Coming: How to Scrape Live Football Data Without Getting Blocked
48 teams. 104 matches. 39 days. Here’s the infras […]
Unknown
2026-06-12

From Kickoff to Dataset: Building the Ultimate World Cup 2026 Data Archive for AI Models
The biggest football tournament in history is also the […]
Unknown
2026-06-12

Why Every World Cup 2026 App Needs a Proxy Strategy (And Most Don’t Have One)
You built the features. You designed the UX. You planne […]
Unknown
2026-06-12

5 Tests Every Proxy Buyer Should Run Before Committing to a Plan
Most people buy proxies the way they buy a mattress. Th […]
Unknown
2026-06-12

How to Manage Multiple TikTok Accounts Without Bans: A Complete 2026 Guide
Understanding TikTok’s Platfor ...
Xyla Huxley
2026-06-12
