Web Scraper API
Fetch real-time data from 100+ websites,No development or maintenance required.
SCRAPING SOLUTIONS
Get accurate and in real-time results sourced from Google, Bing, and more.
With 120+ prebuilt and custom scrapers ready for any use case.
No blocks, no CAPTCHAs—unlock websites seamlessly at scale.
Execute scripts in stealth browsers with full rendering and automation
PROXY INFRASTRUCTURE
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
SCRAPING SOLUTIONS
PROXY INFRASTRUCTURE
DATA FEEDS
Full details on all features, parameters, and integrations, with code samples in every major language.
LEARNING HUB
ALL LOCATIONS Proxy Locations
TOOLS
RESELLER
Get up to 50%
Contact sales:partner@thordata.com
Products $/GB
Fetch real-time data from 100+ websites,No development or maintenance required.
Get real-time results from search engines. Only pay for successful responses.
Execute scripts in stealth browsers with full rendering and automation.
Bid farewell to CAPTCHAs and anti-scraping, scrape public sites effortlessly.
Dataset Marketplace Pre-collected data from 100+ domains.
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
Data for AI $/GB
Pricing $0/GB
Docs $/GB
Full details on all features, parameters, and integrations, with code samples in every major language.
Resource $/GB
EN $/GB
产品 $/GB
AI数据 $/GB
定价 $0/GB
产品文档 $/GB
资源 $/GB
简体中文 $/GB
<–!>

<–!>

In today’s rapidly evolving e-commerce environment, efficiently and accurately acquiring Amazon data has become a necessity for cross-border merchants, market research agencies, and others. Manually scraping data from the vast information on Amazon’s website is akin to searching for a needle in a haystack. This article aims to compare 5 of the best scraping APIs, designed specifically for extracting Amazon ASINs and related data. We will thoroughly compare the core features, applicable scenarios, and costs of these services, to help you make an informed decision, to transform Amazon data into actionable business insights.
● If you need a solution configured with powerful rotation capabilities, that can reliably bypass Amazon’s anti-scraping measures and provide stable output, the Amazon ASIN Scraper API offered by Thordata is the best choice.
● Apify, Bright Data, ScraperAPI, and ScrapingBee each have their advantages, but there are significant differences in price, complexity, and controllability.
● Choosing an Amazon ASIN Scraper API is not about “whether it can scrape,” but rather “whether it is stable, scalable, and compliant in the long term.”
ASIN (Amazon Standard Identification Number) is a unique identifier assigned by Amazon to each product on its platform. It is to Amazon products what ISBN is to books, or UPC is to general merchandise. Every product sold on Amazon, whether by Amazon itself or third-party sellers, is assigned a unique 10-character (alphanumeric) ASIN. This identifier is the cornerstone for searching, sharing links, and managing data within Amazon. For example, when you see “/dp/B0DHRQRLYW” in an Amazon product URL, “B0DHRQRLYW” is the ASIN of that product.
Finding the ASIN is very simple, and there are usually two direct methods:
• First method: Check the URL of the product detail page.
On any product detail page on Amazon, the browser’s address bar will contain the ASIN, which usually appears after “/dp/.”
For example, if you search for “camera” and click on any product to enter the detail page, you can see the ASIN identifier for that product in the top link.
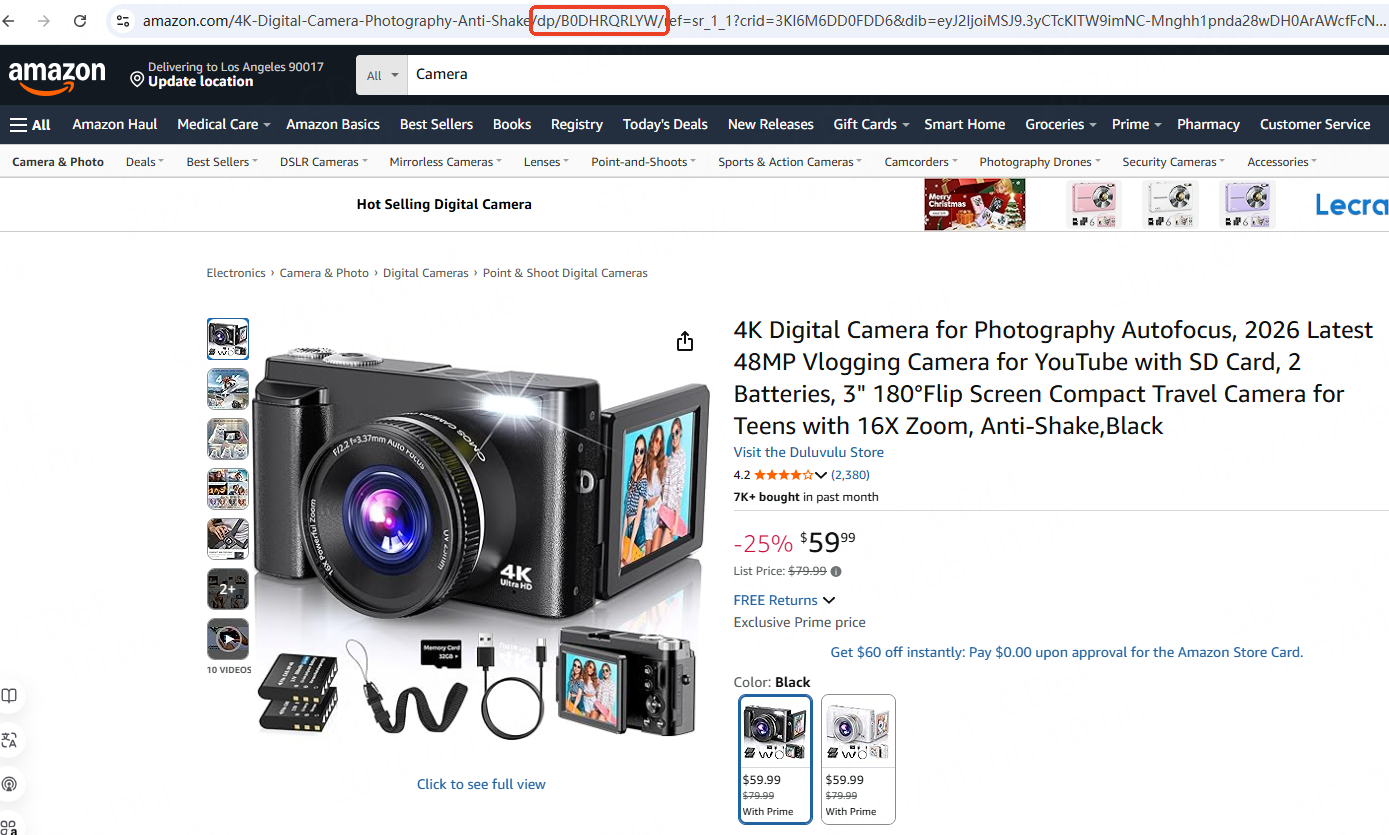
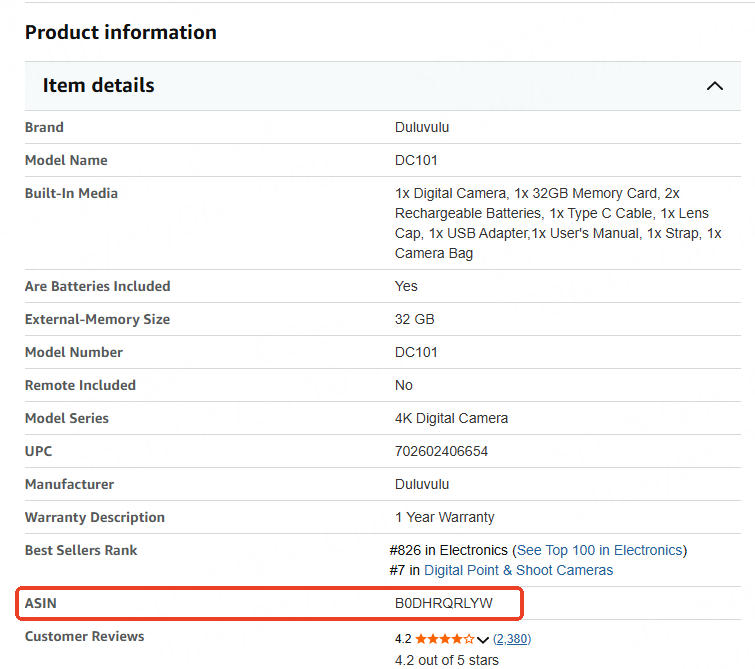
• Second method: look in the product information section.
Scroll down to the “Product Information” section on the product detail page, and you will see an entry labeled “ASIN,” with the code following it being the ASIN identifier for that product.
The enormous scale of global e-commerce — according to a report by Research Nester, the e-retail market is expected to reach $44.3 trillion by 2026 — has generated a massive demand for data. Furthermore, research by Mordor Intelligence indicates that to meet this demand, the global web scraping market is expanding at an approximate compound annual growth rate of 14.2%, and is expected to reach $2 billion by 2030, with the e-commerce sector likely to be the industry with the largest impact on the compound annual growth rate at 3.2%. Collecting product data from platforms like Amazon and eBay has become a basic need for market participants, but Amazon’s sophisticated anti-scraping mechanisms, such as IP rate limiting, behavioral fingerprint detection, and dynamic content loading, make it challenging for traditional self-built scraper scripts to achieve efficiency in development and maintenance costs. This is the fundamental significance of the professional Amazon ASIN Scraper API: it encapsulates a series of complex key technologies into a ready-to-use service.
Using the Amazon Scraper API, essentially leveraging its integrated key features to systematically overcome the limitations of traditional scraping:
• Professional proxy rotation mechanism: The large residential proxy network maintained by the API provider can automatically and frequently switch IP addresses, effectively avoiding IP blocks triggered by excessively high request frequency.
• Complete JavaScript rendering capability: For pages that rely on JavaScript to dynamically load prices, images, and comments, the built-in headless browser environment of the API can ensure that the fully rendered final HTML is obtained, ensuring data integrity.
• Intelligent request management and retry strategy: The system automatically handles request intervals and manages session cookies, and intelligently retries when encountering network errors or temporary anti-scraping responses (such as 503 status codes), maintaining a high success rate without needing to manually write fault-tolerance logic.
• Continuously updated parsing engine: In the face of frequent structural changes in Amazon’s pages, the API provider proactively updates its data parsing rules, ensuring long-term accuracy in extracted fields (such as price and ranking), so users do not need to continuously monitor and fix parsing scripts.
• Scalable concurrent architecture: The API backend is designed to handle massive concurrent requests, allowing users to easily scale scraping tasks based on their needs, from dozens to millions of ASINs, without worrying about server load or bandwidth bottlenecks.
• Standardized data delivery: Raw HTML is cleaned, deduplicated, and converted into structured JSON or CSV format, saving the cumbersome data cleaning steps, allowing data to flow directly into databases or analysis tools.
Structured ASIN data scraped from Amazon, like crude oil, can inject powerful momentum into businesses in various fields after refinement and analysis. Here are four main application scenarios:
For sellers operating directly on the Amazon platform, data is their radar and navigational tool. They need to stay updated on market dynamics to make precise decisions.
• Dynamic pricing strategy: Automatically track competitors’ price changes through the API and adjust their own pricing accordingly to maintain competitiveness or maximize profits. McKinsey noted in a report that “using competitor price data for dynamic pricing can improve profits by 5%.”
• Listing optimization: Analyze the titles, keywords, descriptions, and images of similar best-selling products, optimize their own listings to improve search rankings and conversion rates.
• Inventory and product selection decisions: Track changes in rankings and the number of ratings to predict product demand, and manage inventory levels. At the same time, discover market gaps and seek blue ocean product opportunities with high demand but relatively low competition.
• Advertising effectiveness evaluation: Combine sales data to analyze the actual sales and ranking improvements brought about by specific keywords or advertising campaigns.
These organizations provide in-depth market analysis reports for brands and investors, the authority of their conclusions relies on comprehensive and accurate primary Amazon data.
• Market trend analysis: Analyze category trends, tracking the scale growth and emerging hotspots of different categories over time, and assess the overall market size and market shares of various brands.
• Competitive landscape depiction: Calculate brand shares, monitor product line expansions, pricing strategies, and changes in user reviews of major players.
• Consumer insights: By aggregating and analyzing vast amounts of review data, extract general opinions from consumers regarding product features, pros and cons, and services.
• Producing paid reports: Package the cleaned and analyzed data into industry analysis reports with high commercial value, and sell them to businesses for strategic planning, investment due diligence, and product development.
This group includes ERP software developers, e-commerce store assistants, bulk collection and upload tool SaaS providers, who do not sell products directly but provide infrastructure and services for sellers.
• Developing core data functionalities: Use the API to develop product selection, pricing, and monitoring tools for their own products, such as helping users copy high-quality listings with one click, or automatically sync inventory and prices across multiple platforms.
• Providing data services: Provide customers with data-driven operational services, such as providing inventory alerts, advertising keyword recommendations, and product optimization reports for managed clients as value-added services.
• Building industry solutions: Combine Amazon data with other data sources (such as social media trends and Google Trends), to create smarter business intelligence (BI) products.
Price comparison platforms like CamelCamelCamel and Keepa, base their core business model entirely on a continuous flow of Amazon data.
• Product information aggregation: Scrape product information from Amazon and other e-commerce platforms, clean and normalize the data, to build a unified product database, providing users with a one-stop price comparison service.
• Providing price comparison features: For the same product, compare prices, shipping costs, and delivery times across different sellers (including Amazon itself and third parties), to provide users with the best options.
• Historical price tracking and alerts: Run Amazon price monitoring, record the Amazon price history for each ASIN, and generate price trend charts.
• Implementing price drop alert features: Allow users to set target prices, and when the price drops to that level, send Amazon price drop alerts and notifications via email or push.
• Monetizing traffic: Users click links on the price comparison platform to purchase on Amazon, and the platform earns affiliate marketing commissions. Accurate price monitoring and alert features are key to attracting and retaining users.
With so many options available, how can you make a scientific comparison? You need to establish a multidimensional evaluation framework, which is far more complex than just comparing price lists. Here are several key factors to focus on when making your selection:
1. Success rate and stability: This is the most critical metric. Ask the service provider for historical success rate data, and it’s best to test the stability of performance on target Amazon sites (like .com, .de, .jp) using the free quota.
2. Proxy quality and type: Residential proxies are typically more reliable than data center proxies. Understand the size of the proxy pool, its purity (whether it has been abused), and the rotation strategy. A good proxy solution is key to continuously obtaining data.
3. Ability to cope with anti-scraping measures: Does the service provider actively update its strategies to cope with Amazon’s blocking technologies? Does it automatically handle CAPTCHA, fingerprint detection, and request rate limits?
4. Accuracy and granularity of data extraction: Can it accurately extract every field you need (such as lightning deal prices, prices displayed only to Prime members)? Can the parsing engine keep up with changes in Amazon’s frontend interface?
5. Latency and speed: The freshness of the data is crucial. What is the response time of the API? Does it support high concurrent requests to meet your bulk scraping needs for Amazon ASINs?
6. Usability and integration support: Is the API documentation clear? Does it provide SDKs or code samples for mainstream programming languages (like Python, Node.js, etc.)? Does it support Webhooks and direct integration with Google Sheets or data warehouses?
7. Scalability and reliability: Can the service scale easily as your business volume grows? Is there a Service Level Agreement (SLA) in place? Is technical support timely and effective?
8. Transparency of pricing models and total cost of ownership (TCO): Are there any other hidden fees (like bandwidth or storage fees) besides the cost per request? Are failed requests charged? Does the pricing model fit your usage habits (pay-per-request, by traffic, subscription-based)? Calculate your expected usage and estimate the total cost of ownership (TCO).
9. Compliance and data security: Does the service provider adhere to the Robots.txt protocol and website terms of service? Is its data acquisition method within legal and ethical frameworks? Is your data secure during transmission and storage?
Thordata is a one-stop platform designed for enterprise-level data collection needs, and its Amazon Scraper API is highly favored for its excellent stability and ability to bypass complex anti-scraping mechanisms. Behind this service is its own high-quality residential proxy network, which means your requests come from real residential IP addresses, significantly reducing the risk of being identified and blocked by Amazon. Unlike traditional proxy servers, Thordata deeply integrates the proxy infrastructure with intelligent scraping logic, offering a ready-to-use Amazon scraping API, creating a complete workflow for real-time IP rotation, automatic CAPTCHA bypassing, intelligent request scheduling, and instant data parsing. For users needing continuous, stable, and large-scale acquisition of Amazon product, ranking, review, and ASIN list data, Thordata offers them a highly integrated option. Aimultiple ranks Thordata as one of the best proxy service providers.
1. Features
• Amazon-specific optimization: Its scraping logic and request patterns are specifically optimized for Amazon’s page structure and risk control system, aimed at maximizing the success rate.
• Intelligent proxy integration: The backend automatically mixes residential proxies and high-quality isp proxies, striking a balance between cost and effectiveness, and achieving automatic rotation to reduce the risk of being blocked.
• Intelligent anti-anti-scraping strategy: Automatically simulates human browsing behavior, handles CAPTCHA challenges, reducing the need for manual intervention.
• High-precision parsing engine: Even when faced with frequent adjustments to Amazon’s page structure, it can maintain accurate extraction of data fields (such as price and ranking).
• SaaS platform + API dual mode: In addition to the API, a visual operation platform is also provided, allowing users to directly configure tasks, view scraping history, and export data, lowering the accessibility barrier for non-technical users.
• Data quality assurance: Built-in data cleaning and deduplication mechanisms, ensure that the returned structured data is accurate and clean, and can be used directly for analysis.
2. Types of Scraped Data
🛒 Product details: Title, brand, ASIN, description.
💰 Price data: Current price, original price, discounted price, coupon information, discount rate.
🏷️ Sales and ranking metrics: Ranking, estimated sales, inventory status (FBA/FBM).
⭐️ Reviews and ratings: Rating stars, number of ratings, text and date of the latest reviews.
🛍️ Seller insights: Self-owned/third-party identification, seller information, delivery methods.
3. Pricing
• $0.00/2,000 Credits(Free Trial)
• $30.00/30,000 Credits
• $125.00/150,000 Credits
• $500.00/750,000 Credits
• $1,500.00/3,000,000 Credits
Apify is a powerful cloud web scraping platform, which productizes the capabilities of web scrapers in the form of “Actors.” You can directly use pre-built Amazon crawling Actors created by the community or official sources on the platform, or you can use its visual tools or code (Python/JavaScript) to build fully customized crawlers. This model provides developers with a high degree of flexibility, to design data scraping processes according to unique needs.
1. Features
• Visual crawler builder: Simple scraping tasks can be configured by point-and-click without a deep coding background.
• Powerful “Actor” model: Each crawler is an independent, schedulable, and monitorable application unit.
• Integrated runtime environment: Each Actor runs in a containerized sandbox with built-in proxy configuration, storage, and scheduling capabilities, making management easy.
• Flexible scheduling and monitoring: Supports scheduled runs, error retries, and detailed execution logs.
2. Types of Scraped Data
• General Actors can typically extract basic information (title, price, images).
• Advanced custom Actors can extract any visible data, including 4-star/3-star ratings, etc.
• Capable of handling dynamic content such as pagination and infinite scrolling.
3. Pricing
• Starter: $39/ month + pay as you go
• Scale: $199/ month + pay as you go
• Business: $999/ month + pay as you go
Bright Data (formerly Luminati) is one of the largest proxy network providers in the world, and its Web Scraper API is built on a vast proxy infrastructure. It places particular emphasis on compliance and the legality of data collection, providing solutions that comply with regulations such as GDPR for large enterprises. Its Amazon scraping tool can pinpoint IP locations down to the city level, which is a powerful feature for companies needing to analyze regional pricing strategies.
1. Features
• Vast proxy network: With over 150 million residential IPs covering every corner of the globe.
• Comprehensive data collection solutions: In addition to the Scraper API, it also offers various tools such as Browser API and Scraper Studio.
• Enterprise-level compliance and stability: All proxy traffic is obtained with user consent, making it suitable for businesses sensitive to legal risks.
• Powerful dashboard and analytics tools: Provides detailed usage reports and success rate analysis.
2. Types of Scraped Data
• Product information: Title, brand, description, color, style, etc.
• Seller information: Seller name, seller ID, etc.
• Price information: Initial price, final price, currency, etc.
3. Pricing
• Pay as you go:$1.5 /1K Records
• 510K Records: $499 Billed monthly
• 1M Records: $999 Billed monthly
• 2.5M Records: $1999 Billed monthly
ScraperAPI simplifies complex web scraping into a simple HTTP API call, aimed at addressing common pain points of web scraping with just a few lines of code. It simplifies the development process by automatically handling proxy rotation, CAPTCHAs, and browser fingerprints. For those who want to quickly integrate a basic Amazon data scraping capability, without wanting to deeply manage a pool of proxies, this is a quite attractive option.
1. Features
• Minimalistic API design: You can start scraping with just one HTTP request, allowing for fast integration.
• Automatic proxy management and retry mechanism: Claims to intelligently select the best proxy to ensure a high success rate.
• Basic JavaScript rendering support: Can handle some pages that require simple JS execution.
2. Types of Scraped Data
• In “Raw HTML” mode, you can obtain the full source code of the page.
• In “Auto Parsing” mode, you can extract basic structured fields from Amazon product pages, such as price, title, description, images, etc.
• For reviews, rankings, and other secondary page data, additional API requests may be needed.
3. Pricing
• Hobby: $49/ month/ 100,000 API Credits
• Startup: $149/ month/ 1,000,000 API Credits
• Business: $299/ month/ 3,000,000 API Credits
• Scaling: $475/ month/ 5,000,000 API Credits
ScrapingBee’s core selling point lies in its native support for headless browsers (like Chrome), specially tackling web pages that are heavily rendered by JavaScript. Although most Amazon product pages are static, certain elements (such as lazy-loaded images, interactive Q&A modules) or JavaScript-based ads may affect data scraping. ScrapingBee loads pages through a real browser environment, ensuring that it can retrieve the fully rendered final HTML.
1. Features
• One-click JavaScript rendering: You only need one API parameter to switch to headless browser mode.
• Screenshot feature: Can capture page screenshots for visual verification or archiving.
• Concurrent processing: Supports sending multiple URLs for scraping at once to improve batch processing efficiency.
2. Types of Scraped Data
• In rendering mode, it can retrieve the complete DOM content that matches what a person sees in the browser.
• For Amazon, this means reliably obtaining price, inventory, and discount information loaded through JS.
3. Pricing
• Freelance: $49/ month/ 250,000 API Credits
• Startup: $99/ month/ 1,000,000 API Credits
• Business: $249/ month/ 3,000,000 API Credits
• Business +: $599/ month/ 8,000,000 API Credits
| Provider | Key Features | Storage Options | Best Use Cases | Limitations | Billing Model | Pricing |
| Thordata | Intelligent anti-bot & IP ban bypass | Snowflake/Amazon S3/Webhooks | Large-scale ASIN data collection | Custom requirements require contacting sales | Pay per successful request | 7-day free trial: 2,000 Credits |
| Apify | Visual crawler builder | Apify Datasets | Rapid prototyping and scripted tasks | Complex configuration | Pay by runtime | $39/month |
| Brightdata | Real-time data scraping | API output/Webhooks | High-difficulty anti-bot environments | High pricing, steep learning curve | Pay per request | $499/month |
| ScraperAPI | Intelligent proxy rotation | API response/Local storage | Small to medium-scale scraping | Limited customization | Pay by API credits | $49/month / 100,000 Credits |
| ScrapingBee | Built-in headless browser rendering | API response | Front-end rendered pages | Rendering mode consumes credits quickly | Pay per API call | $49/month / 250,000 Credits |
One project our team was involved in was developing a competitive monitoring system for the camera category for a cross-border e-commerce seller. This seller focuses on selling digital cameras and photography accessories and needs to regularly scrape Amazon’s bestsellers list to track popular product trends. By using the web scraper API to automate the collection of ASINs, prices, and ranking data for the camera category, we helped him achieve daily updates, avoiding the inefficiencies and errors of manual operations.
Tools: Thordata web scraper API + BeautifulSoup
Here is a simple Python example that you can reproduce, you only need to apply for an API key from Thordata to run it (the free trial provides ample credits):
import requests
api_key = "YOUR_API_KEY"
url = "https://universalapi.thordata.com/request"
payload = {
"url": "https://www.amazon.com/Best-Sellers-Digital-Cameras/zgbs/electronics/281052",
"type": "html",
"js_render": True,
"proxy_type": "residential"
}
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
html_content = response.text
# Use BeautifulSoup to further extract ASINs (example)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
asins = [item['data-asin'] for item in soup.find_all('div', {'data-asin': True}) if item['data-asin']]
print("Extracted ASINs:", asins[:10])
else:
print("Request failed:", response.text)This code sends requests to the Amazon digital camera bestseller list, Thordata automatically enables residential proxy rotation, JavaScript rendering, and retries, ensuring a high success rate, allowing you to easily extract the ASIN list after receiving the complete HTML.
The project results show that we successfully achieved the following key outcomes:
• Efficient ASIN extraction: Successfully scraped the ASINs of the top 100 best-selling cameras in a single request, covering popular models such as the KODAK PIXPRO FZ55 (16MP 5X optical zoom) and the Dylanto children’s instant print camera.
• Real-time market insights: Through daily monitoring, helping sellers quickly identify camera market trends for early 2026, including the rise of instant print cameras, portable vlogging cameras, and entry-level 4K point-and-shoot cameras.
• Significant business improvement: Price tracking and inventory optimization based on this ASIN data, directly drove a sales increase of over 30% for the seller, and effectively mitigated the risk of unsold inventory.
In today’s data-driven operations, choosing the right Amazon ASIN Scraper API is the first step in building your data competitive advantage. When selecting a tool, be sure to thoroughly assess its success rate, proxy quality, data depth, and long-term stability—these core pillars. Through this in-depth comparison, we can see that whether it is Thordata, which pursues extreme stability and bypassing capabilities, or Apify, which offers a high degree of flexibility, their core value lies in helping you avoid the cumbersome script building and achieve one-stop data delivery. For the vast majority of business users seeking reliable and scalable data supply, integrating Thordata’s Amazon Scraper API is the most cost-effective choice.
We hope the information provided is helpful. However, if you have any further questions, feel free to contact us at support@thordata.com or via online chat.
<–!>
Frequently asked questions
Is it legal to scrape Amazon?
Scraping publicly available Amazon data often exists in a legal gray area, its legality depends on your specific methods of operation, data usage, and whether you comply with its terms of service. To mitigate risks, it is recommended to use professional Amazon Scraper API services (like Thordata) for compliant scraping, Such services use legitimate residential proxies and respect access restrictions.
How to check Amazon ASIN number?
You can find the ASIN in two simple ways: First, view the code after “/dp/” in the product detail page URL (for example, B09G9FPHY6 in …/dp/B09G9FPHY6); Second, look for the clearly labeled “ASIN” field in the “Product Information” section of the product page.
Can I use a web scraper on Amazon?
Technically feasible, but strongly advised against deploying a generic scraper on your own. Amazon has a powerful anti-scraping system that will quickly block automated requests. A stable and reliable method is to use a dedicated Amazon Scraper API, which can effectively bypass detection through strategies like rotating proxies.
<–!>
About the author
Anna is a content specialist who thrives on bringing ideas to life through engaging and impactful storytelling. Passionate about digital trends, she specializes in transforming complex concepts into content that resonates with diverse audiences. Beyond her work, Anna loves exploring new creative passions and keeping pace with the evolving digital landscape.
The thordata Blog offers all its content in its original form and solely for informational intent. We do not offer any guarantees regarding the information found on the thordata Blog or any external sites that it may direct you to. It is essential that you seek legal counsel and thoroughly examine the specific terms of service of any website before engaging in any scraping endeavors, or obtain a scraping permit if required.
 Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
AI Data Collection: How to Source, Prepare, and Use Data for Smarter AI
Artificial intelligence is onl ...
ning loop. Xyla Huxley
2026-06-24

Proxy vs Firewall: What’s the Difference?
Firewalls and proxies are used ...
Kael Odin
2026-06-23

Building a Real-Time Sports Video Pipeline That Feeds Your LLM Without Getting Cut Off
You need fresh sports video in ...
Xyla Huxley
2026-06-23

The Quiet Revolution: How Sports Video Is Reshaping Multimodal LLM Training Methodologies
The academic community spent a ...
Xyla Huxley
2026-06-23

The $400K Mistake: Thinking AI Model Training for Sports Video Only Needed GPUs
We approved the budget in Janu ...
Xyla Huxley
2026-06-23

Why Your LLM’s Sports Video Understanding Depends on Residential Proxy Infrastructure You Haven’t Built Yet
You spent six months optimizing your LLM’s transf […]
Unknown
2026-06-23

How to Create Original Facebook Ad Creatives and Reduce Rejection Risk
Learn how to create original F ...
Jenny Avery
2026-06-22

Training a Cooking Robot? Your YouTube Data Pipeline Needs to See Every Kitchen in the World
Robotics companies training vi ...
Xyla Huxley
2026-06-18

YouTube Video Collection at Scale: A Complete Python Pipeline with Residential Proxy Integration
This is a practical guide for ...
Xyla Huxley
2026-06-18
